Our (Katrina Evtimova and I) initial motivation was to see if we could `fix’ a spurious correlation in a dataset by just collecting some examples and fine-tuning on those examples. We also had interest in understanding what changed as we did this and whether the correlation became spurious in another way.
We collected a dataset of cows, with the spurious correlation being the texture of the cow. In particular, they were all rainbow-related and the model (pretrained ResNet18 on imagenet) placed none of them in the top 3 results. An example image is shown to the right. Finetuning on just a set of cows resulted in the model shifting its attention to predicting just cows. This was foreseeable and also not good because the result was that its performance on ImageNet suffered dramatically.
Consequently, we tried a test where we made a new training set consisting of 10 spurious cows (rainbow cows) and a single image from each of the classes in ImageNet for a total of 1010 images. We then tested on two datasets:
Test Cows: Another 15 spurious cows.
ImageNet Val: The ImageNet validation set.
To our surprise, this did ok. ImageNet didn’t suffer too much and the model became predictive of the cows. This suggested further investigation.
Was this effect predictable?
The main question now was if this effect was predictable. If this is actually a legitimate strategy for addressing spurious correlations, then we’d expect that there would be a pronounced and monotonic improvement in the resulting ImageNet efficacies when including different numbers of classes from the range [100, 1000]. The ideal would be to preserve the efficacy on the 50k-size validation set while succeeding at learning these new cows. We would also like to see that not just the Top{1, 5} preserve, but also that the probability distributions do not change too much.
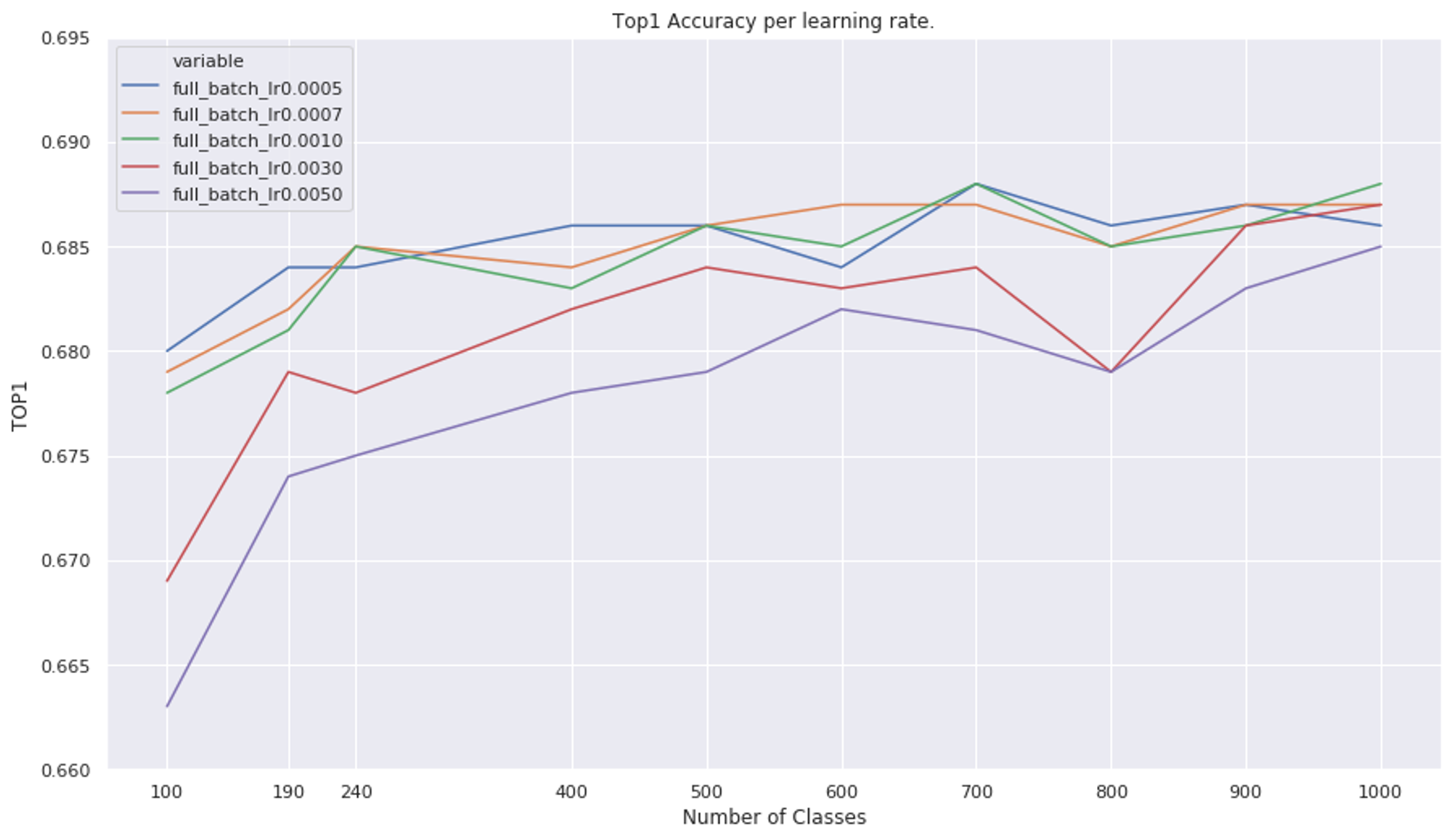
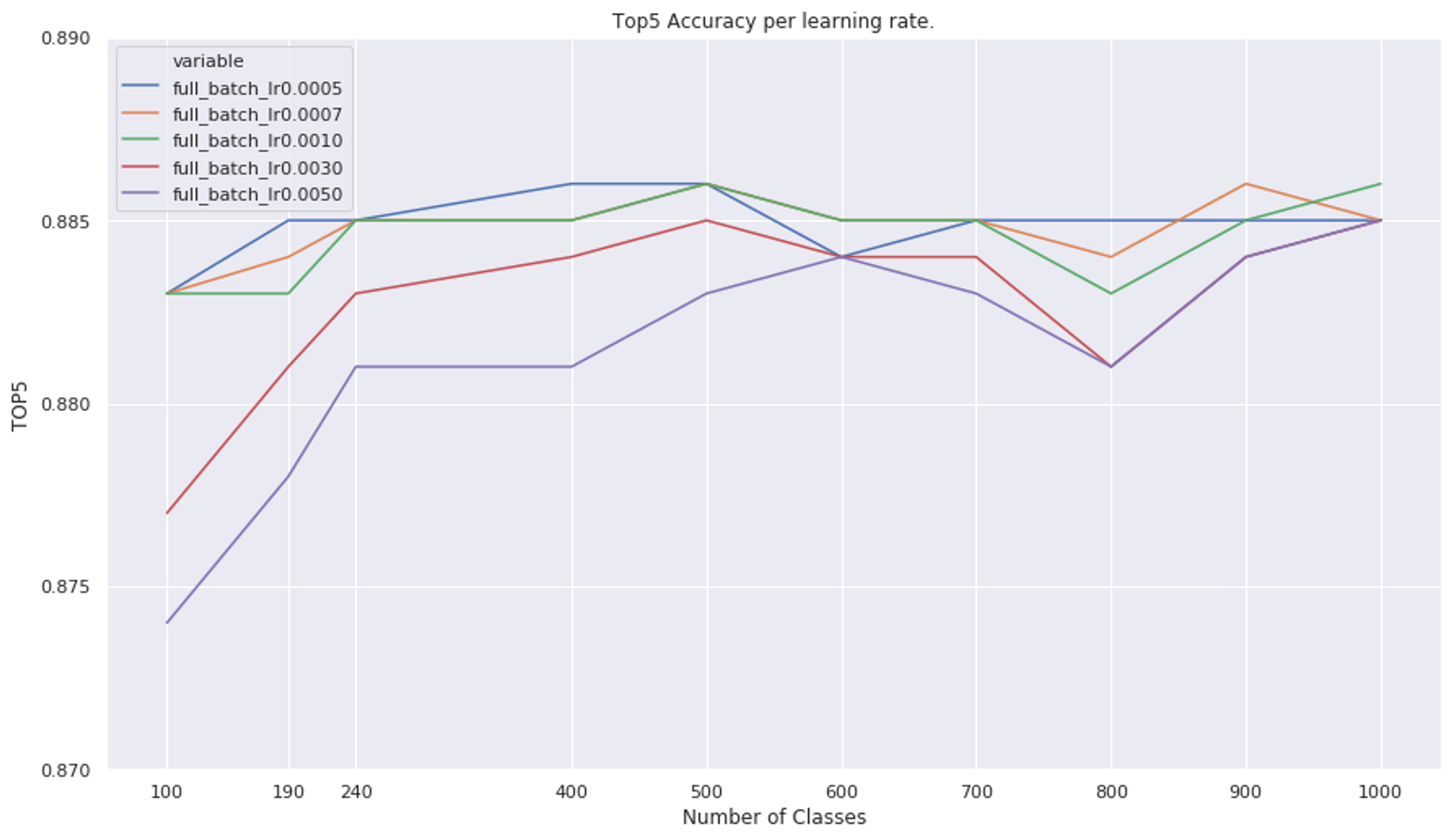
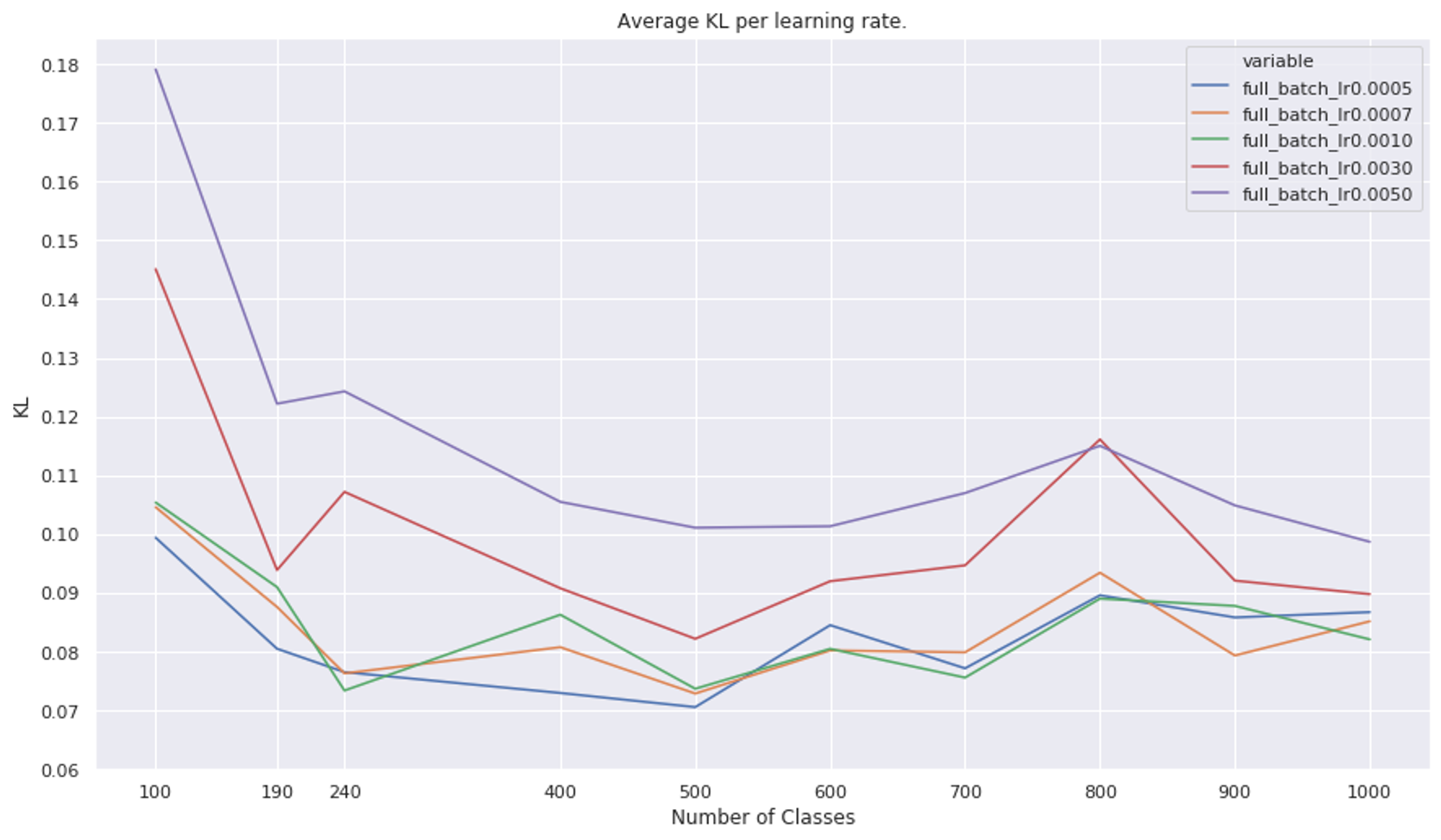
The figures below show the Top1 and Top5 accuracies by number of classes in the training set. Below them is a similar graph but for KL, where KL is given by:
Here, θ are the pre-trained ResNet18 weights and θ′ are the weights after training the model until the Test Cows have accuracy > 0.9. The training set consists of one example from each of N classes, plus 10 spurious cows from the same distribution as Test Cows. We use a single seed for all of these runs, as well as do full batch training.
Looking at the Top1 and Top5 accuracies, and remembering that the original Top1 and Top5 accuracies are 69.57 and 89.24, we see that the lower learning rate models (1e-3 and below) do a better job of preserving the accuracy. There is a loose trend that the higher the number of classes, the more likely it is to keep the accuracy, but this is not consistent enough to confidently suggest it as being legitimate.
The Top 1 accuracy by number of classes in the training set.
The Top 5 accuracy by number of classes in the training set
Considering the graphs of KL below, we see the same effect wrt learning rate; The lower the learning rate, the more likely it is that the model has a low average KL. However, we again see that it is not a consistent effect. All of the low learning rates (1e-3 and lower) seem to have their nadir at 500 classes, which is contrary to any hypothesis we could make around the more classes the better.
To make the inconsistency argument explicit, it seems that while 500 is approximately as good as 1000 classes, it appears that 800 is worse. These results are not indicative of this approach being a reliable method for addressing spurious correlations.
The average KL on the Imagenet Validation set between the pretrained model before and after it was finetuned on the Imagenet+SpuriousCows dataset.
Does this help the model learn about cows?
Did this approach help the model learn about “cow”, about “rainbow cow”, or does it now just predict cows more?
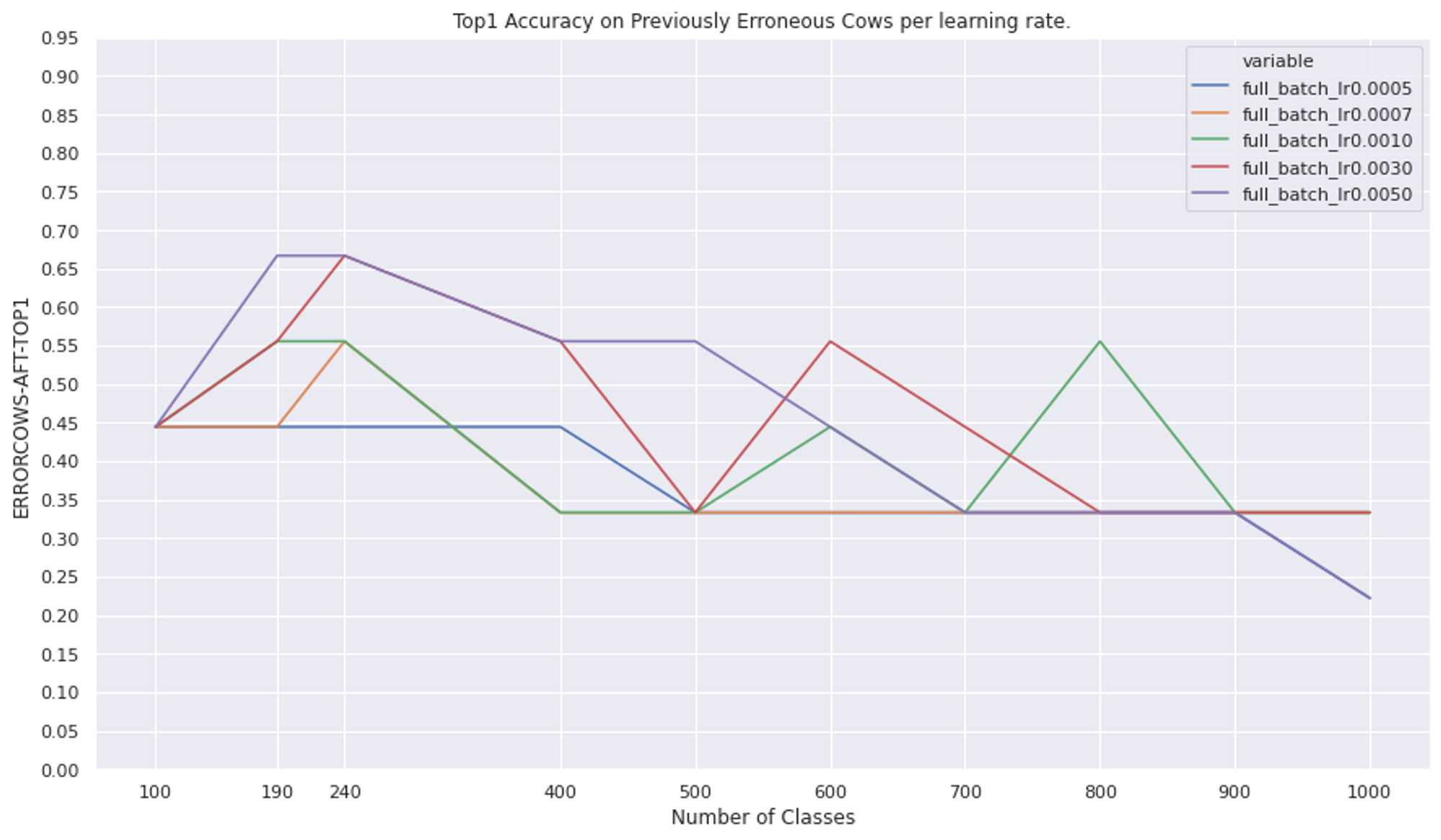
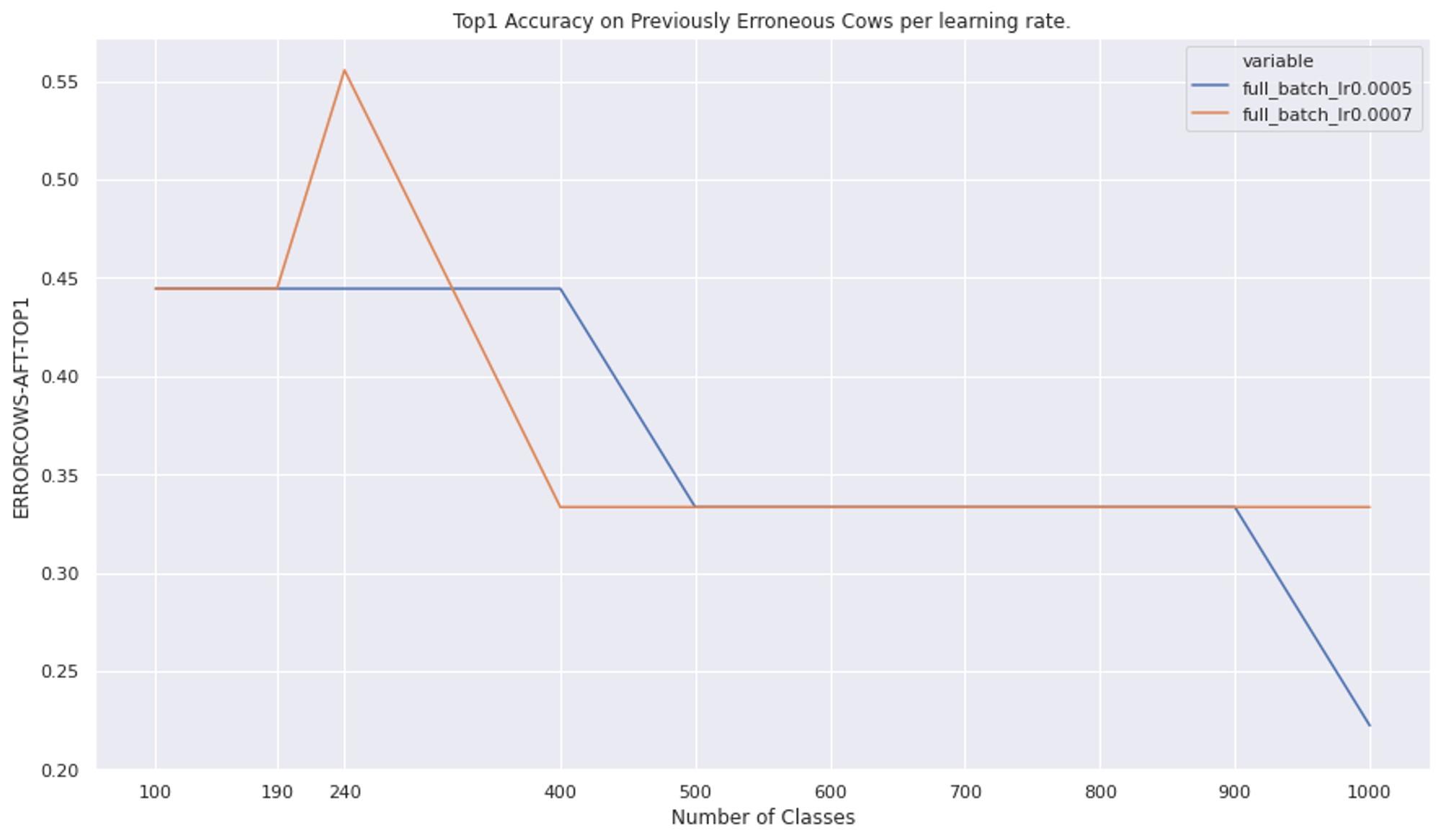
The two figures below show the results of testing on a held out set of nine cows after training on the Imagenet + Rainbow Cows training set. All of the images in this held out set were marked incorrectly beforehand training and none of them are rainbow cows.
Erroneous Cows Top 1 after training on an additional held out set of cows that the model did not originally understand.
Zoomed in graph of the above isolating just two of the models.
If fixing this spurious correlation meant the models now knew “cow”, then we’d expect the results to be successful across the board. In other words, we’d expect that no matter the learning rate, the model would reach a high accuracy.
On the other hand, if the model just learned about “rainbow cow”, then we’d see it have a low accuracy regardless of learning rate on this held out set.
Finally, if the model had just learned to predict cows a little bit more, then we’d expect that the higher the learning rate, the higher the accuracy on this held out set. This is because the model would have a tougher time very slightly increasing the cow efficacy with higher learning rates than with lower learning rates. The result would be that for this challenging further test set, it would be more likely to say it’s a cow in situations where it has been pulled more towards saying indiscriminately that everything is “cow”.
By and large, the figures above suggest the third scenario. All of the models have middling accuracy, but the lower learning rates (blue and orange) are the lowest across the class number.
Discussion
We don’t really want a model that can just do cows a bit better at the expense of lots of other data. And we do see the latter happening given that roughly ~300 images from the validation set flip from being recognized to not being recognized.
The most likely story here is that the lower the learning rate, the easier it is for the model to wiggle its way into a space where it doesn’t diminish too much from the original results while learning to predict cow just a little bit more. That’s not what we want in our models, and so our conclusion is that this procedure is not likely to address the main concern of no longer having this spurious correlation. However, it’s possible that a way to do that would be to use the techniques we made to find the spurious correlation, then train on that from scratch.